Introducing TC Getter
Calculate Big-O time complexity of Python code in the browser. Try it out
Algorithms and Data Structures Cheatsheet
A quick reference guide to some of the most commonly used algorithms in DSA
Table of contents
Time and Space Complexity. Big O Notation#
Time Complexity
Demonstrates how fast the computing time of an algorithm escalates as the size of the input increases.
When solving problems, we can compare algorithm Time Complexity to input size and validate if given algorithm fits to input size.
Big O Notation
Analyzes asymptotic - answers how fast function grows.
Associates problem size n with processing time to solve problem t:
n - size
6 ┤ *
│ *
4 ┤ *
│ *
2 ┤ *
└──┬──┬──┬──┬──┬──┬───
0 1 2 3 4 5 6 t - timeBest, Worst, and Average Cases
- Best: Function performs minimal operations required to solve problem on input of
nelements - Worst: Maximum amount of steps
- Average Average amount of steps
In real-time computing, the worst-case execution time is often of particular concern since it is important to know how much time might be needed in the worst case to guarantee that the algorithm will always finish on time.
Example - Bogosort (Permutation sort)
Bogosort creates permutation of input array and checks if it's sorted.
- Best: - array initially sorted, so it's needed n operations to check if each element on right place
- Worst: - since bogosort creates random permutation each time, in worst case it will never produce sorted permutation
- Average - amount of permutations is
Order of Magnitude
A description of a function in terms of Big notation typically provides only an upper bound on the growth rate of the function.
To calculate Order of Magnitude:
Discard constants:
Pick only the most significant function:
Typical Operations with Big O Notation
- Adding two functions or complexities
- Multiplying two functions or complexities
Example
- - Time Complexity
- - Processor single-core speed
Time calculations for n = 8 and n = 100:
- How much time it takes for 1 operation computed on single-core processor
- If maximum
n = 8seconds. So, computer will be able to compute it in reasonable time. - If maximum
n = 100→ number with 158 digits years. This is times longer than our universe 🪐 exists!
Growth rate comparison

Space Complexity
Space complexity measures the memory required by an algorithm as a function of the input size
Common Space Complexities:
- - constant space
- - linear space, and
- - quadratic space.
Optimizing Space complexity can lead to more efficient algorithms, especially in large-scale data processing.
Additional materials
Two pointers#
Iterating two pointers across an array to search for a pair of indices satisfying some condition in linear time.
Variants
Opposite directional
Same directional
Fast and slow pointers
When to use
- Sequential data structure (arrays, linked lists)
- Process pairs
- Remove duplicates from a sorted data
- Detect cycle in array
- Find a pair, triplet, or a subarray that satisfies a specific condition
- Reversing, partitioning, swapping, or rearranging
- String manipulation
- Array partitioning
- Etc. like Two sum or container with water variations
Problem examples
Given a 1-indexed array of integers numbers that is already sorted in non-decreasing order, find two numbers such that they add up to a specific target number.
class Solution: def twoSum(self, numbers: List[int], target: int) -> List[int]: low = 0 high = len(numbers) - 1 while low < high: sum = numbers[low] + numbers[high] if sum == target: return [low + 1, high + 1] elif sum < target: low += 1 else: high -= 1 return [-1, -1]Given the head of a singly linked list, return the middle node of the linked list.
If there are two middle nodes, return the second middle node.
class Solution: def middleNode(self, head): slow = fast = head while fast and fast.next: slow = slow.next fast = fast.next.next return slowGiven n non-negative integers representing an elevation map where the width of each bar is 1, compute how much water it can trap after raining.
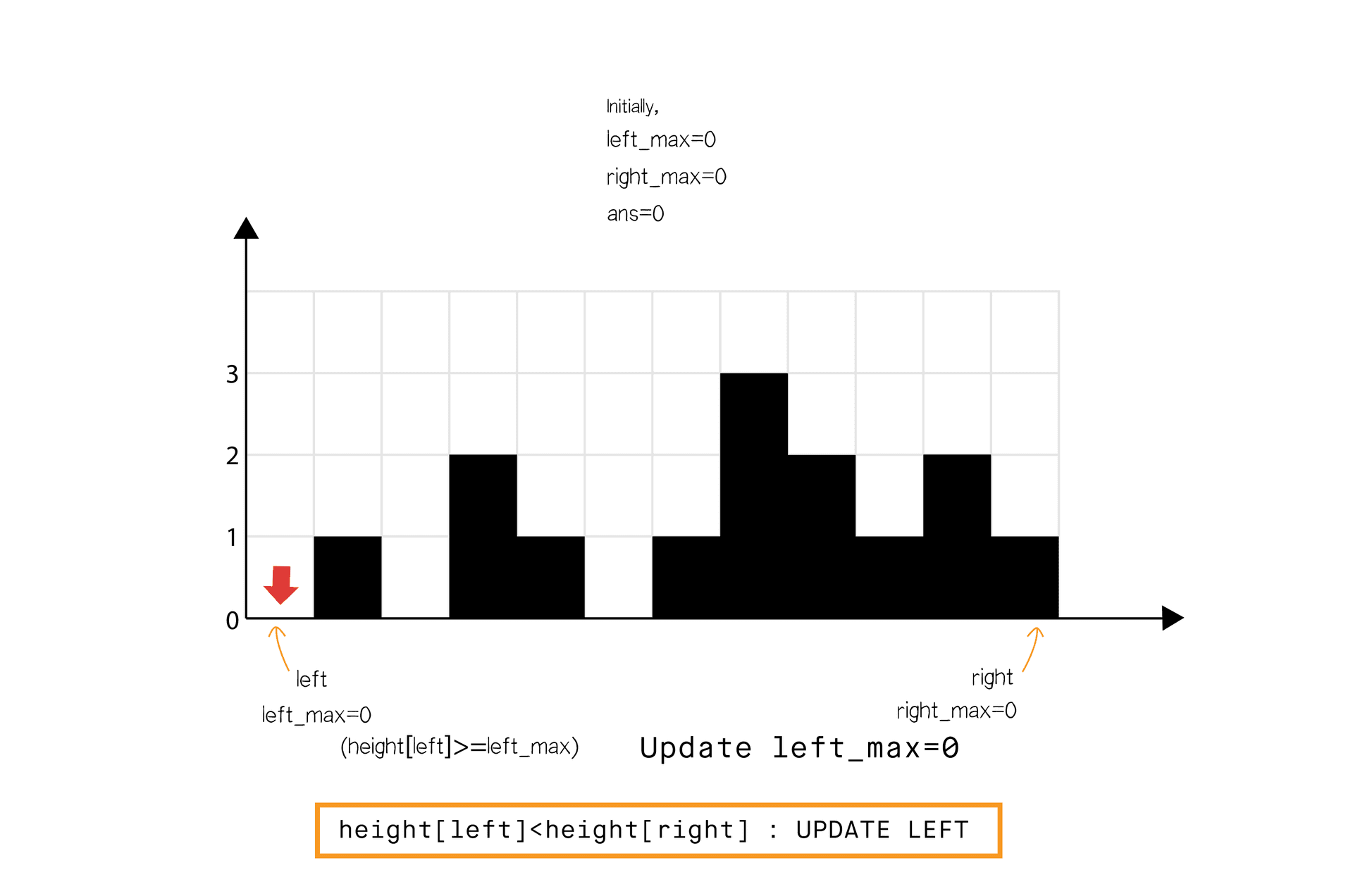
class Solution: def trap(self, height: List[int]) -> int: left, right = 0, len(height) - 1 ans = 0 left_max, right_max = 0, 0 while left < right: if height[left] < height[right]: left_max = max(left_max, height[left]) ans += left_max - height[left] left += 1 else: right_max = max(right_max, height[right]) ans += right_max - height[right] right -= 1 return ansAdditional materials
Sliding window#
Maintain a dynamic window that slides through the array or string, adjusting its boundaries as needed to track relevant elements or characters.
Sliding window converts multiple nested loops into single loop, reducing the time complexity from or to .
Variants
- Fixed window size
- Variable window size
- Initialize window indices: Start with
startandendpointers at the first element. - Expand the window: Increment the
endpointer to expand the window if conditions are met. - Process the window: Perform required operations when the window meets criteria.
- Adjust the window size: Move the
startpointer to adjust size and meet desired criteria.
- Initialize window indices: Start with
- Growing window
- Shrinking window
- Multiple windows: Maintaining overlapping or disjoint windows can help solve problems more efficiently.
When to use
- Contiguous data: array, linked list, string, or stream
- Processing subsets of elements: The problem requires repeated computations on a contiguous subset of data elements (a subarray or a substring) of fixed or variable length
- Find longest, shortest or target values of a sequence
Problem patterns
- Running Average: Efficiently calculate the average of a fixed-size window in a data stream.
- Formulating Adjacent Pairs: Process adjacent pairs in an ordered structure for easy access and operation.
- Target Value Identification: Adjust window size to search efficiently for specific values or subarrays.
- Longest/Shortest/Most Optimal Sequence: Identify the desired sequence in a collection by sliding a window through it.
Real World usage
String Manipulation:
- Substring Search: Finding the longest substring without repeating characters.
- Pattern Matching: Searching for a pattern within a larger string efficiently.
- Text Processing: Analyzing text data for specific patterns or occurrences.
Array Manipulation:
- Subarray Problems: Finding the maximum sum, product, or average of a subarray of fixed or variable size.
- Data Processing: Analyzing time series data, such as stock prices or sensor readings, to identify trends or anomalies.
Window-based Algorithms:
- Sliding Window Aggregations: Calculating moving averages, rolling sums, or other window-based aggregations in data analysis.
- Stream Processing: Handling data streams by maintaining a sliding window over the stream to perform computations in real-time.
Data Compression:
- Sliding window compression algorithms, like LZ77 and its variants, use a window to find repeated patterns in the input data and replace them with references to previous occurrences.
Image Processing:
- In image processing, a sliding window can be employed for tasks such as feature extraction, object detection, or image segmentation.
Signal Processing:
- Time-series data can be analyzed using a sliding window to capture local patterns, trends, or anomalies.
Network Traffic Analysis:
- Anomaly Detection: Identifying anomalous patterns in network traffic by analyzing data within sliding windows.
- Performance Monitoring: Monitoring network performance metrics, such as latency or throughput, over time using sliding windows.
Optimization Problems:
- Resource Allocation: Optimizing resource allocation or scheduling decisions based on dynamic window-based constraints.
Natural Language Processing (NLP):
- Text Classification: Analyzing text documents and classifying them into categories based on sliding window features.
- Named Entity Recognition: Identifying entities such as names, locations, or organizations within text using sliding window-based algorithms.
Problem examples
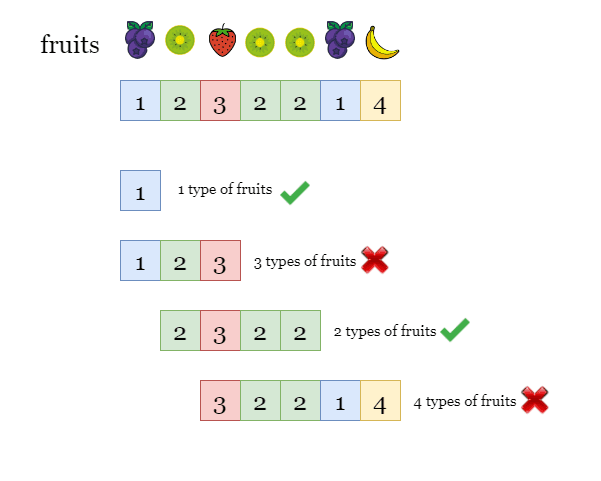
You are visiting a farm that has a single row of fruit trees arranged from left to right. The trees are represented by an integer array fruits where fruits[i] is the type of fruit the ith tree produces.
You want to collect as much fruit as possible. However, the owner has some strict rules that you must follow:
- You only have two baskets, and each basket can only hold a single type of fruit. There is no limit on the amount of fruit each basket can hold.
- Starting from any tree of your choice, you must pick exactly one fruit from every tree (including the start tree) while moving to the right. The picked
fruitsmust fit in one of your baskets. - Once you reach a tree with fruit that cannot fit in your baskets, you must stop.
- Given the integer array
fruits, return the maximum number offruitsyou can pick.
Example:
Let's compare Brute Force approach with Sliding window:
class Solution: def totalFruit(self, fruits: List[int]) -> int: max_picked = 0 for left in range(len(fruits)): basket = set() right = left while right < len(fruits): if fruits[right] not in basket and len(basket) == 2: break basket.add(fruits[right]) right += 1 max_picked = max(max_picked, right - left) return max_pickedIn second approach, two nested loops converted into a single loop thus improving Time Complexity from to :
class Solution: def totalFruit(self, fruits: List[int]) -> int: basket = {} max_picked = 0 left = 0 for right in range(len(fruits)): basket[fruits[right]] = basket.get(fruits[right], 0) + 1 while len(basket) > 2: basket[fruits[left]] -= 1 if basket[fruits[left]] == 0: del basket[fruits[left]] left += 1 max_picked = max(max_picked, right - left + 1) return max_pickedYou are given an integer array nums and an integer k. Find the maximum subarray sum of all the subarrays of nums that meet the following conditions:
- The length of the subarray is
k - All the elements of the subarray are distinct.
Return the maximum subarray sum of all the subarrays that meet the conditions. If no subarray meets the conditions, return 0.
Example:
class Solution: def maximum_subarray_sum(self, nums, k): res = cur_sum = 0 last_seen_to_idx = {} last_seen = -1 for i, num in enumerate(nums): cur_sum += num if i >= k: cur_sum -= nums[i - k] last_seen = max(last_seen, last_seen_to_idx.get(num, -1)) if i - last_seen >= k: res = max(res, cur_sum) last_seen_to_idx[num] = i return resGiven an array of positive integers nums and a positive integer target, return the minimal length of a subarray whose sum is greater than or equal to target. If there is no such subarray, return 0 instead.
Example:
class Solution: def minSubArrayLen(self, target: int, nums: List[int]) -> int: left = 0 right = 0 sumOfCurrentWindow = 0 res = float('inf') for right in range(0, len(nums)): sumOfCurrentWindow += nums[right] while sumOfCurrentWindow >= target: res = min(res, right - left + 1) sumOfCurrentWindow -= nums[left] left += 1 return res if res != float('inf') else 0Given a string s and an integer k, return the maximum number of vowel letters in any substring of s with length k.
Example:
class Solution: def maxVowels(self, s: str, k: int) -> int: vowels = set("aeiou") count = 0 for i in range(k): count += int(s[i] in vowels) answer = count for i in range(k, len(s)): count += int(s[i] in vowels) count -= int(s[i - k] in vowels) answer = max(answer, count) return answerAdditional materials
Intervals#
Performing operations on set of intervals. Typical interval problem deals with array of overlapping intervals e.g. [[1, 3], [3, 5]].
Common tasks with intervals
- Merging intersecting intervals
- Medium56. Merge Intervals
- Inserting new intervals into existing sets
- Medium57. Insert Interval
- Schedule tasks
- Medium621. Task Scheduler
- Arrange meeting rooms
- Medium253. Meeting Rooms II
- Determining the minimum number of intervals needed to cover a given range
Corner cases
- No intervals
- Single interval
- Two intervals
- Non-overlapping intervals
- An interval totally consumed within another interval
- Duplicate intervals (exactly the same start and end)
- Intervals which start right where another interval ends -
[[1, 2], [2, 3]]
When to use
- Given intervals
- Find union / intersection / gaps
Real World usage
- Event scheduling
- Resource allocation: Schedule tasks for the OS based on task priority and the free slots in the machine’s processing schedule
- Time slot consolidation
Problem examples
Given an array of intervals where intervals[i] = [starti, endi], merge all overlapping intervals, and return an array of the non-overlapping intervals that cover all the intervals in the input.
Example:
class Solution: def merge(self, intervals: List[List[int]]) -> List[List[int]]: intervals.sort(key=lambda x: x[0]) merged = [] for interval in intervals: if not merged or merged[-1][1] < interval[0]: merged.append(interval) else: merged[-1][1] = max(merged[-1][1], interval[1]) return mergedor depending on sorting algorithm
You are given an array of non-overlapping intervals intervals where intervals[i] = [starti, endi] represent the start and the end of the ith interval and intervals is sorted in ascending order by starti. You are also given an interval newInterval = [start, end] that represents the start and end of another interval.
Insert newInterval into intervals such that intervals is still sorted in ascending order by starti and intervals still does not have any overlapping intervals (merge overlapping intervals if necessary).
Return intervals after the insertion.
Note that you don't need to modify intervals in-place. You can make a new array and return it.
Example:
Problem can be dropped down into 2 subproblems:
- Find correct place for
newInterval- Since
intervalsis sorted, we can utilize binary search.
- Since
- Merge it with any overlapping intervals
- Linear iteration over intervals
class Solution: def insert( self, intervals: List[List[int]], newInterval: List[int] ) -> List[List[int]]: # If the intervals vector is empty, return a vector containing the newInterval if not intervals: return [newInterval] n = len(intervals) target = newInterval[0] left, right = 0, n - 1 # Binary search to find the position to insert newInterval while left <= right: mid = (left + right) // 2 if intervals[mid][0] < target: left = mid + 1 else: right = mid - 1 # Insert newInterval at the found position intervals.insert(left, newInterval) # Merge overlapping intervals res = [] for interval in intervals: # If res is empty or there is no overlap, add the interval to the result if not res or res[-1][1] < interval[0]: res.append(interval) # If there is an overlap, merge the intervals by updating the end of the last interval in res else: res[-1][1] = max(res[-1][1], interval[1]) return resYou are given an array of CPU tasks, each labeled with a letter from A to Z, and a number n. Each CPU interval can be idle or allow the completion of one task. Tasks can be completed in any order, but there's a constraint: There has to be a gap of at least n intervals between two tasks with the same label.
Return the minimum number of CPU intervals required to complete all tasks.
Example:
A → B → idle → A → B → idle → A → B.After completing task A, you must wait two intervals before doing A again. The same applies to task B. In the 3 interval, neither A nor B can be done, so you idle. By the 4 interval, you can do A again as 2 intervals have passed.
class Solution: def leastInterval(self, tasks: List[str], n: int) -> int: counter = Counter(tasks) max_heap = [-val for val in counter.values()] heapify(max_heap) res = 0 while max_heap: cycle = n + 1 tasks = [] while cycle and max_heap: task = -heappop(max_heap) cycle -= 1 if task > 1: tasks.append(-(task - 1)) while tasks: heappush(max_heap, tasks.pop()) res += n + 1 if max_heap else n - cycle + 1 return res
Given an array of meeting time intervals intervals where intervals[i] = [starti, endi], return the minimum number of conference rooms required.
class Solution: def minMeetingRooms(self, intervals: List[List[int]]) -> int: intervals.sort() end_times = [] for start, end in intervals: if not end_times or end_times[0] > start: heapq.heappush(end_times, end) else: heapq.heapreplace(end_times, end) return len(end_times)Additional materials
Linked List#
This section focuses on in-place operations with Linked Lists.
Properties
- Sequential data structure (like array, unlike tree)
- Slow access, but fast add / delete operations
Variants
- Singly-linked list
┌─────┐ ┌─────┐ ┌─────┐
│ A ├────►│ B ├────►│ C ├────►null
└─────┘ └─────┘ └─────┘- Doubly-linked list
┌─────┐ ┌─────┐ ┌─────┐
null◄────┤ A │◄───►│ B │◄───►│ C ├────►null
└─────┘ └─────┘ └─────┘- Circular-linked list
┌─────┐ ┌─────┐ ┌─────┐
│ A ├────►│ B ├────►│ C │
└─────┘ └─────┘ └─────┘
▲ │
└───────────────────────┘Example of Singly-linked List
class ListNode: def __init__(self, val=0, next=None): self.val = val self.next = next first_node = ListNode(1) second_node = ListNode(2) first_node.next = second_node┌─────┐ ┌─────┐
│ 1 ├───►│ 2 ├───►null
└─────┘ └─────┘Dummy node technique
If operation is going to be performed on head or tail node, we can create dummy node, and point dummy.next to head. It helps not to handle edge cases for head only:
dummy = ListNode() dummy.next = head # perform operations on dummy.next # we don't need to handle head specifically return dummy.nextTypical operations with Linked Lists
- List Node operations
- Swap nodes Medium1721. Swapping Nodes in a Linked List
- Remove node Medium237. Delete Node in a Linked List
- Swap nodes
- Whole List operations
- Reverse Easy206. Reverse Linked List
- Reorder Medium143. Reorder List
- Split Medium725. Split Linked List in Parts
- Merge 2 or more lists Hard23. Merge k Sorted Lists
- Reverse
- Search
- Find middle Easy206. Reverse Linked List
- Find cycle Easy141. Linked List Cycle
- Find middle
- Custom data structures with Linked List under the hood
- Medium146. LRU Cache
- Hard460. LFU Cache
When to use
- Linked list restructuring: The input data is given as a linked list, and the task is to modify its structure without modifying the data of the individual nodes.
- In-place modification: The modifications to the linked list must be made in place, that is, we’re not allowed to use more than additional space.
Problem examples
Given the head of a singly linked list, reverse the list, and return the reversed list.
Iterative approach
class Solution: def reverseList(self, head: ListNode) -> ListNode: prev = None curr = head while curr: next_temp = curr.next curr.next = prev prev = curr curr = next_temp return prevRecursive approach
Note: Space complexity grows to because each head is stored in call stack.
class Solution: def reverseList(self, head: ListNode) -> ListNode: if (not head) or (not head.next): return head p = self.reverseList(head.next) head.next.next = head head.next = None return pGiven head, the head of a linked list, determine if the linked list has a cycle in it.
Return true if there is a cycle in the linked list. Otherwise, return false.
┌─────┐ ┌─────┐ ┌─────┐
│ 1 ├───►│ 2 ├───►│ 3 ├─┐
└─────┘ └─────┘ └─────┘ │
▲ │
└───────────────────────────┘class Solution: def hasCycle(self, head: ListNode) -> bool: if head is None: return False slow = head fast = head.next while slow != fast: if fast is None or fast.next is None: return False slow = slow.next fast = fast.next.next return TrueYou are given the head of a singly linked-list. The list can be represented as:
L0 → L1 → … → Ln - 1 → Ln
Reorder the list to be on the following form:
L0 → Ln → L1 → Ln - 1 → L2 → Ln - 2 → …
You may not modify the values in the list's nodes. Only nodes themselves may be changed.
Visual algorithm
1. Initial list:
┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐
│ 1 ├───►│ 2 ├───►│ 3 ├───►│ 4 ├───►│ 5 ├───►null
└─────┘ └─────┘ └─────┘ └─────┘ └─────┘
1. Find middle (middle points to 3):
┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐
│ 1 ├───►│ 2 ├───►│ 3 ├───►│ 4 ├───►│ 5 ├───►null
└─────┘ └─────┘ └─────┘ └─────┘ └─────┘
▲
middle
1. Reverse second half (4->5 becomes 5->4):
┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐
│ 1 ├───►│ 2 ├───►│ 3 ├───►│ 4 ◄────│ 5 │
└─────┘ └─────┘ └─────┘ └─────┘ └─────┘
prev
1. Start merging (first=1, second=5):
┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐
│ 1 ├─┐ │ 2 ├───►│ 3 ├───►│ 4 ◄────│ 5 │
└─────┘ │ └─────┘ └─────┘ └─────┘ └─────┘
│ ▲
└───────────────────────────────────────┘
1. Final reordered list:
┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐
│ 1 ├───►│ 5 ├───►│ 2 ├───►│ 4 ├───►│ 3 ├───►null
└─────┘ └─────┘ └─────┘ └─────┘ └─────┘class Solution: def reorderList(self, head: ListNode) -> None: if not head: return # find the middle of linked list [Problem 876] # in 1->2->3->4->5->6 find 4 slow = fast = head while fast and fast.next: slow = slow.next fast = fast.next.next # reverse the second part of the list [Problem 206] # convert 1->2->3->4->5->6 into 1->2->3->4 and 6->5->4 # reverse the second half in-place prev, curr = None, slow while curr: curr.next, prev, curr = prev, curr, curr.next # merge two sorted linked lists [Problem 21] # merge 1->2->3->4 and 6->5->4 into 1->6->2->5->3->4 first, second = head, prev while second.next: first.next, first = second, first.next second.next, second = first, second.nextAdditional materials
Heap: Introduction#
Heap is a complete binary tree where each node is smaller than its children (for min heap). This property is called Heap invariant, heap must always comply to it.
Priority Queue vs Heap
- Priority queue
- Abstract data structure (like stack or queue) that behaves like queue (First In, First Out)
- Each element has priority - the higher propriety element comes first
- Specifies behavior of data structure
- Doesn't define internal implementation
- Heap
- Implements of Priority queue
Variants
- Min heap - each parent node smaller of equal to its children
- Max heap - each parent node bigger or equal to its children
Operations on heap
- Add node
- Add new node to end of heap
- Swap the node with parent if it's bigger than parent
- At most, swaps could be made since heap - Complete binary tree. In complete binary tree, height =
- Remove node
- Take tree root and remove it from tree
- Place last element to root
- Swap with children to achieve Heap invariant
- At most, swaps could be made
- Heapify
- Start from last leave
- If node doesn't satisfy Heap invariant, recursively heapify subtree
- Move up the tree until the entire tree satisfies the Heap invariant
- The total amount of swaps is
Array representation of Heap
Heap usually represented as array:
- Nodei stored in array by index
i - Nodei left and right children could be found by index
2 * iand2 * i + 1 - It's convenient to store nodes starting from index
1
Example or Max heap
Tree representation:
Complete binary tree of height 2
Level Tree
0: 9
/ \
1: 7 8
/
2: 5 - all levels are filled except for last layerArray representation with indices:
0 index is blank because 0 * 2 = 0
↓
┌───┬───┬───┬───┬───┐
Value │ - │ 9 │ 7 │ 8 │ 5 │
└───┴───┴───┴───┴───┘
Index 0 1 2 3 4When to use
K-th element
Top K elements
Heap sort
Sort subset of elements resulting to TC optimization from to where k is heap size
Problem examples
Given an integer array nums and an integer k, return the kth largest element in the array.
Note that it is the kth largest element in the sorted order, not the kth distinct element.
Can you solve it without sorting?
Example:
class Solution: def findKthLargest(self, nums, k): heap = [] for num in nums: heapq.heappush(heap, num) if len(heap) > k: heapq.heappop(heap) return heap[0]You are given two integer arrays nums1 and nums2 sorted in non-decreasing order and an integer k.
Define a pair (u, v) which consists of one element from the first array and one element from the second array.
Return the k pairs (u1, v1), (u2, v2), ..., (uk, vk) with the smallest sums.
Example:
class Solution: def kSmallestPairs(self, nums1: List[int], nums2: List[int], k: int) -> List[List[int]]: heap, seen, res = [(nums1[0] + nums2[0], 0, 0)], {(0, 0)}, [] while heap and len(res) < k: _, i, j = heappop(heap) res.append([nums1[i], nums2[j]]) for i2, j2 in [(i, j + 1), (i + 1, j)]: if i2 < len(nums1) and j2 < len(nums2) and (i2, j2) not in seen: seen.add((i2, j2)) heappush(heap, (nums1[i2] + nums2[j2], i2, j2)) return resHere, is the size of nums1 and is the size of nums2:
Real World usage
- Network routing
- Dijkstra's algorithm uses heaps to efficiently find the shortest path between network nodes by maintaining shortest distances as priorities.
- Process scheduling
- Operating systems use priority queues (heaps) to manage which process gets CPU time next based on priority levels.
- Resource allocation
- In cloud computing, heaps help distribute resources (like memory or CPU) by maintaining a priority queue of requests from different applications.
- Machine learning
- K-nearest neighbors algorithm uses heaps to efficiently maintain the k closest points during distance calculations and similarity searches.
Additional materials
- Competitive Programmer's Handbook - Chapter 9: Data Structures
- Tech Interview Handbook - Heap
- basecs - Learning to Love Heaps
- basecs - Heapify All The Things With Heap Sort
- Yale University - Heaps
- LeetCode - Master Heap: Understanding 4 Patterns Where Heap Data Structure is Used
- LeetCode - Heap Explore Card
Heap: Two heaps#
Two heaps approach used to find out middle of moving dataset
It assumes having
- Max heap to store maximum of part of dataset
- Min heap to store minimum of part of dataset
Algorithm for finding median of k-size dataset
- Initialization - placing elements to heaps by
- Initialize min heap and max heap
- Min heap will store elements right to the median (bigger)
- Max heap will store elements left to the median (smaller)
- Place every item in min heap
- If min heap size exceeds
k // 2- Pop element from min heap (it will be smallest one)
- Place to max heap
- Initialize min heap and max heap
- Find median -
keven - Average of min heap and max heap rootskodd - Max heap root
- Shift sliding window
- Perform steps 2-3
When to use
- Linear data: The input data is linear but not sorted
- Stream of data
- Find Max / Min:
- Find maximums / minimums / maximum and minimum of 2 datasets
Problem examples
Suppose LeetCode will start its IPO soon. In order to sell a good price of its shares to Venture Capital, LeetCode would like to work on some projects to increase its capital before the IPO. Since it has limited resources, it can only finish at most k distinct projects before the IPO. Help LeetCode design the best way to maximize its total capital after finishing at most k distinct projects.
You are given n projects where the ith project has a pure profit profits[i] and a minimum capital of capital[i] is needed to start it.
Initially, you have w capital. When you finish a project, you will obtain its pure profit and the profit will be added to your total capital.
Pick a list of at most k distinct projects from given projects to maximize your final capital, and return the final maximized capital.
The answer is guaranteed to fit in a 32-bit signed integer.
Example:
class Solution: def findMaximizedCapital( self, k: int, w: int, profits: List[int], capital: List[int] ) -> int: min_capitals = [(c, p) for c, p in zip(capital, profits)] heapq.heapify(min_capitals) max_profits = [] for _ in range(k): while min_capitals and min_capitals[0][0] <= w: c, p = heapq.heappop(min_capitals) heapq.heappush(max_profits, -p) if max_profits: w += -heapq.heappop(max_profits) return wThe median is the middle value in an ordered integer list. If the size of the list is even, there is no middle value. So the median is the mean of the two middle values.
- For examples, if
arr = [2,3,4], the median is3. - For examples, if
arr = [1,2,3,4], the median is(2 + 3) / 2 = 2.5.
You are given an integer array nums and an integer k. There is a sliding window of size k which is moving from the very left of the array to the very right. You can only see the k numbers in the window. Each time the sliding window moves right by one position.
Return the median array for each window in the original array. Answers within 10-5 of the actual value will be accepted.
Example:
Window position Median--------------- -----[1 3 -1] -3 5 3 6 7 11 [3 -1 -3] 5 3 6 7 -11 3 [-1 -3 5] 3 6 7 -11 3 -1 [-3 5 3] 6 7 31 3 -1 -3 [5 3 6] 7 51 3 -1 -3 5 [3 6 7] 6
class Solution: def medianSlidingWindow(self, nums: List[int], k: int) -> List[float]: def clean(h, is_min): while h and rm.get(h[0] if is_min else -h[0], 0): rm[h[0] if is_min else -h[0]] -= 1 heapq.heappop(h) rm, lo, hi, res = {}, [], [], [] for i in range(k): heapq.heappush(lo, -nums[i]) for _ in range(k // 2): heapq.heappush(hi, -heapq.heappop(lo)) for i in range(k, len(nums) + 1): res.append(-lo[0] if k % 2 else (-lo[0] + hi[0]) / 2) if i == len(nums): break out, in_num = nums[i - k], nums[i] rm[out] = rm.get(out, 0) + 1 bal = -1 if out <= -lo[0] else 1 if lo and in_num <= -lo[0]: heapq.heappush(lo, -in_num) bal += 1 else: heapq.heappush(hi, in_num) bal -= 1 if bal < 0: heapq.heappush(lo, -heapq.heappop(hi)) if bal > 0: heapq.heappush(hi, -heapq.heappop(lo)) clean(lo, False) clean(hi, True) return resAdditional materials
Real World usage
Two heaps approach is used when median calculation needed
- Video platforms: median age of the viewers
- Gaming matchmaking: Matching players of similar skill levels
Heap: Top K Elements#
The top k elements pattern is crucial for efficiently finding a specific number of elements, k, from a dataset.
Maintains a heap of size k while iterating through the list of elements.
Time Complexity
Without this pattern, sorting the whole collection is , plus to pick top k elements. The top k pattern achieves by selectively tracking compared elements, using a heap.
Using Heap
A heap is ideal for managing the smallest or largest k elements. By using a max heap for smallest elements and a min heap for largest, we can maintain ordered elements with quick access to the smallest or largest.
Operating Procedure
- Insert first k elements into the appropriate heap.
- Min heap for largest elements.
- Max heap for smallest elements.
- For remaining elements:
- In min heap (for largest elements), replace the smallest (top) with any found larger element.
- In max heap (for smallest elements), replace the largest (top) with any found smaller element.
Efficiency
Time complexity of Top K approach using heap:
- - insertions and removals
- - processing all elements
- - retrieving all
kelements, due to reorganization after each removal.
Time complexity comparison
n - number of all items. k - top k elements
- Brute force -
- Sorting -
- Heap -
Typical problems
- Easy703. Kth Largest Element in a Stream
- Medium767. Reorganize String
- Medium973. K Closest Points to Origin
When to use
- Unsorted List Analysis: Task involves extracting a specific subset (largest, smallest, most/least frequent) from an unsorted list, either as the final goal or an intermediate step.
- Identifying a Specific Subset: To identify a subset based on criteria like top k,
kth largest/smallest, or k most frequent, indicating the top k elements pattern is a fit.
How to identify Top K pattern
- Top k element
- Smallest / Biggest element
- Most / Least frequent k elements
- Furthest / Nearest
- Given Unsorted data
Pitfalls
- Sometimes mathematical approach faster
- Sometimes other patterns faster: Top K Frequent Elements
- Quickselect - Average Time Complexity
- Heap - Average Time Complexity
- If data is sorted, use binary search or others
- If need to find one extremum, heap is not needed
Problem examples
Given an integer array nums and an integer k, return the k most frequent elements. You may return the answer in any order.
Example:
class Solution: def topKFrequent(self, nums: List[int], k: int) -> List[int]: heap = [] for num, freq in Counter(nums).items(): heapq.heappush(heap, (freq, num)) if len(heap) > k: heapq.heappop(heap) return [num for freq, num in heap]Given a string s, rearrange the characters of s so that any two adjacent characters are not the same.
Return any possible rearrangement of s or return "" if not possible.
Example:
class Solution: def reorganizeString(self, s: str) -> str: ans = [] pq = [(-count, char) for char, count in Counter(s).items()] heapify(pq) while pq: count_first, char_first = heappop(pq) if not ans or char_first != ans[-1]: ans.append(char_first) if count_first + 1 != 0: heappush(pq, (count_first + 1, char_first)) else: if not pq: return '' count_second, char_second = heappop(pq) ans.append(char_second) if count_second + 1 != 0: heappush(pq, (count_second + 1, char_second)) heappush(pq, (count_first, char_first)) return ''.join(ans)Given an array of points where points[i] = [xi, yi] represents a point on the X-Y plane and an integer k, return the k closest points to the origin (0, 0).
The distance between two points on the X-Y plane is the Euclidean distance (i.e., √(x1 - x2)2 + (y1 - y2)2).
You may return the answer in any order. The answer is guaranteed to be unique (except for the order that it is in).
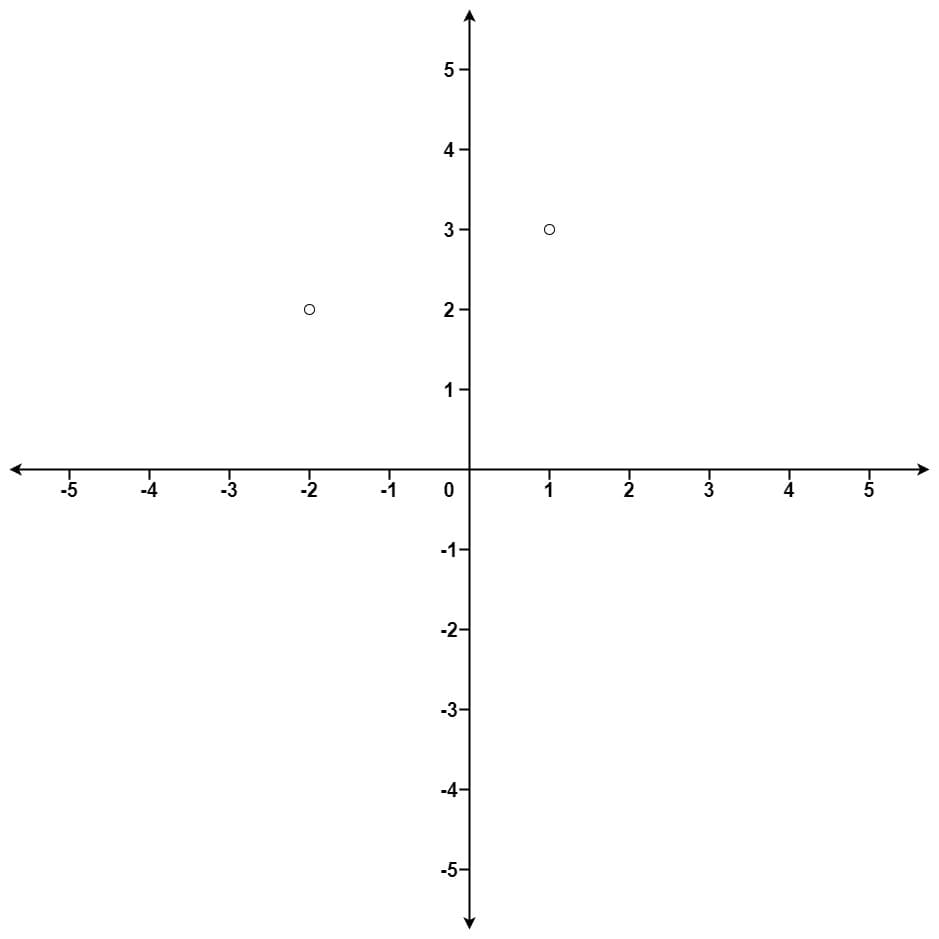
Example:
class Solution: def kClosest(self, points: List[List[int]], k: int) -> List[List[int]]: dist_idx_heap = [] for i, (x, y) in enumerate(points): dist = sqrt(x**2 + y**2) heapq.heappush(dist_idx_heap, (-dist, i)) if len(dist_idx_heap) > k: heapq.heappop(dist_idx_heap) res = [] for dist, i in dist_idx_heap: res.append(points[i]) return resReal World usage
Ride-sharing Apps: Efficiently finding the nearest drivers for a user in apps like Uber, prioritizing the closest n drivers without needing to evaluate all city drivers.
Financial Markets: Highlighting top brokers based on transaction volumes or success metrics, sifting through data to spotlight leaders in market activities.
Social Media: Filtering top trending topics by frequency, using the top K elements pattern to analyze hashtags or keywords for content relevancy.
Heap: K-Way Merge#
The K-way merge pattern combines k sorted data structures into a single sorted output.
It works by repeatedly selecting the smallest (or largest) element from among the first elements of each input list and adding it to the output list, continuing until all elements are merged in order.
K-way merge of sorted data could be achieved by:
- Heaps
- Merge sort
Min Heap Approach:
- Insert first element from each list into min heap
- Remove heap's top element, add to output
- Replace with next element from same input list
- Repeat until all elements merged
Divide & Merge (merge sort):
- Divide lists into 2 parts and merge each part
- Continue dividing and merging resulting lists
- Repeat until single sorted list remains
Typical problems
- Medium378. Kth Smallest Element in a Sorted Matrix
- Medium373. Find K Pairs with Smallest Sums
- Hard23. Merge k Sorted Lists
When to use
- Merging sorted arrays/matrix rows/columns into a single sorted sequence
- Finding kth smallest/largest element across multiple sorted collections (like finding median in multiple sorted arrays)
Problem examples
Given an n x n matrix where each of the rows and columns is sorted in ascending order, return the kth smallest element in the matrix.
Note that it is the kth smallest element in the sorted order, not the kth distinct element.
You must find a solution with a memory complexity better than .
Example:
class Solution: def kthSmallest(self, matrix: List[List[int]], k: int) -> int: min_heap = [(row[0], i, 0) for i, row in enumerate(matrix)] heapify(min_heap) while k: val, i, j = heappop(min_heap) k -= 1 if j + 1 < len(matrix): heappush(min_heap, (matrix[i][j + 1], i, j + 1)) return valYou are given two integer arrays nums1 and nums2 sorted in non-decreasing order and an integer k.
Define a pair (u, v) which consists of one element from the first array and one element from the second array.
Return the k pairs (u1, v1), (u2, v2), ..., (uk, vk) with the smallest sums.
Example:
class Solution: def kSmallestPairs( self, nums1: List[int], nums2: List[int], k: int ) -> List[List[int]]: heap, seen, res = [(nums1[0] + nums2[0], 0, 0)], {(0, 0)}, [] while heap and len(res) < k: _, i, j = heappop(heap) res.append([nums1[i], nums2[j]]) for i2, j2 in [(i, j + 1), (i + 1, j)]: if i2 < len(nums1) and j2 < len(nums2) and (i2, j2) not in seen: seen.add((i2, j2)) heappush(heap, (nums1[i2] + nums2[j2], i2, j2)) return resYou are given an array of k linked-lists lists, each linked-list is sorted in ascending order.
Merge all the linked-lists into one sorted linked-list and return it.
Example:
1->4->5
1->3->4
2->6
Merging them into one sorted list:
1->1->2->3->4->4->5->6
class Solution: def mergeKLists(self, lists: List[Optional[ListNode]]) -> Optional[ListNode]: head = cur = ListNode() heap = [] for i, node in enumerate(lists): if not node: continue heappush(heap, (node.val, i)) while heap: val, min_node_idx = heappop(heap) min_node = lists[min_node_idx] cur.next, cur = min_node, min_node if min_node.next: lists[min_node_idx] = min_node.next heappush(heap, (min_node.next.val, min_node_idx)) return head.nextAdditional materials
Real World usage
Patient Records Aggregation: In healthcare, integrating data from multiple sources like lab results and physician notes into a single record is vital. The K-way merge efficiently combines these data streams, aiding in diagnosis and treatment.
Financial Transaction Merging: For financial institutions, merging transactions from different sources into a single stream is essential for analysis or fraud detection. K-way merge organizes these transactions coherently, improving financial monitoring and analysis.
Log File Analysis: Web services generate logs from multiple servers. Merging these into one stream for analysis requires the K-way merge, making it easier to analyze user behavior or system performance with minimal preprocessing.
Binary search#
Searching algorithm in sorted array
- It works by repeatedly dividing the search interval in half.
- If the target value is less than the middle element, the search continues in the left half;
- if greater, it continues in the right half.
- This process is repeated until the target is found or the interval is empty.
Simple implementation
def binary_search(arr, target): left, right = 0, len(arr) - 1 while left <= right: mid = (left + right) // 2 if arr[mid] == target: return mid # Target found at index mid elif arr[mid] < target: left = mid + 1 # Discard the left half else: right = mid - 1 # Discard the right half return -1 # Target not foundModified Binary search
- Modification of Binary search
- Uses same core conception of dividing search space by 2
- Applies specific conditions or transformations to address unique problems:
Variants
- Binary Search on a Modified Array
- Array is altered
- Medium33. Search in Rotated Sorted Array - sorted and then rotated.
- Binary Search with Multiple Requirements
- Adapt the comparison logic to meet multiple conditions
- Finding a range of targets
- Identifying the leftmost or rightmost occurrences of a value
- Finding Conditions
- Identify boundary conditions
- Easy278. First Bad Version - locating the first instance that meets a specific criterion.
These modifications allow binary search to efficiently tackle a broader range of problems.
Typical problems
- Sorted array
- Find value
- Find range
- Sorted array is modified (rotated)
- Custom comparison (good/bad version)
- Task can be represented by sorted data
- Easy69. Sqrt(x)
- Sorted Matrix
- Find insertion point
Comparison with other algorithms

When to use
- Time Complexity constraint -
- Linear data structure with random access
- Data is sorted
- Data structure that supports direct addressing: array, matrix
- There's no linear data structure, but data is in sorted order
Challenges using Binary Search
- Identify pattern
- Find proper condition
- Not to fall into infinite loop
Notes
- Pre-processing might be needed
- Sort if collection is unsorted
- Precompute if needed
- Medium162. Find Peak Element
- Precompute cumulative sum
- Sometimes we don't want to check found element in loop
while lo < hi: mid = (lo + hi) // 2 if a[mid] < x: lo = mid + 1 else: hi = mid return lo- Beware overflow:
mid = left + (right - left) // 2
# vs
mid = (right + left) // 2- Sometimes we can use built-in b-search like
bisect_leftin Python - Infinite loop:
while l <= r:
...
l = midReal World usage
- Database Searches: Quickly locate records in sorted tables.
- Autocomplete: Efficiently find suggestions from sorted keyword lists.
- Library Catalogs: Identify book locations in sorted catalogs.
- Version Control: Locate specific changes in sorted commit histories (e.g., Git).
- Game Leaderboards: Find player scores in sorted rankings.
- API Pagination: Access specific data points in sorted datasets.
- Image Processing: Determine thresholds in pixel values for segmentation.
Problem examples
Implement pow(x, n), which calculates x raised to the power n (i.e., xn).
Example:
Brute Force
class Solution: def myPow(self, x: float, n: int) -> float: if n == 0: return 1 if n < 0: return 1 / pow(x, -n) return x * pow(x, n - 1)Binary search - Recursive
class Solution: def myPow(self, x: float, n: int) -> float: if n < 0: return 1 / self.myPow(x, -n) if n == 0: return 1 if n % 2: return x * self.myPow(x, n - 1) return self.myPow(x * x, n / 2)Binary search - Iterative
class Solution: def binaryExp(self, x: float, n: int) -> float: if n == 0: return 1 if n < 0: n = -1 * n x = 1.0 / x result = 1 while n != 0: if n % 2 == 1: result *= x n -= 1 x *= x n //= 2 return resultA peak element is an element that is strictly greater than its neighbors.
Given a 0-indexed integer array nums, find a peak element, and return its index. If the array contains multiple peaks, return the index to any of the peaks.
You may imagine that nums[-1] = nums[n] = -∞. In other words, an element is always considered to be strictly greater than a neighbor that is outside the array.
You must write an algorithm that runs in time.
Example:
Input array - [1, 2, 3, 2]

Input array - [1, 2, 3]

Brute Force
def findPeakElement(nums): for i in range(len(nums) - 1): if nums[i] > nums[i + 1]: return i return len(nums) - 1Binary search - Iterative
Hints:
- Local peak, not global
- Items behind array borders (behind first and last) are smaller than boundary items (first and last)

def findPeakElement(self, nums): l, r = 0, len(nums) - 1 while l < r: mid = (l + r) // 2 if nums[mid] > nums[mid + 1]: r = mid else: l = mid + 1 return lAdditional materials
Dynamic Programming#
Dynamic programming is a computer programming technique where an algorithmic problem is first broken down into sub-problems, the results are saved, and then the sub-problems are optimized to find the overall solution.
When to use
- The problem can be divided by subproblems
- The subproblems are overlapping
3 main components:
- State - stores answer for i-th subproblem
- Transition between states - how to get new solution based on previously calculated
- Base case - what's initial or the most atomic subproblem
Approaches
Top-Down - try to solve main problem first, and to solve it solve subproblems recursively up to base case
Bottom-Up - solve subproblems starting from the next one to base case and finishing on main problem
Push DP - update future states based on the current state
Pull DP - calculate the current state based on past states
Top-Down vs Bottom-Up
Top-Down
- Benefits: Easier to implement because of recursion
- Drawbacks: Could not be appliciable because of call stack overflow
Bottom-Up
- Benefits: No recursion. Sometimes is better in space than Top-Down
- Drawbacks: Harder to implement
Hints on using DP
- Think of Base case
- First try recursive Top-Bottom
- Then if Top-Bottom doesn't fit (because of recursive stack or to optimise space, or whatsoever) then try Bottom-Up
Additional materials
Bitwise operations#
Operators
- AND
&- Return1if left and right are1 - OR
|- Return1if left or right are1 - XOR
^- Return1if either left or right bit is1, but not both - NOT
~- Inverts bits:1 → 0,0 → 1~n == -n - 1.- Example:
~1 == -2
- Example:
arr[~k]- accesskthelement in array from the end:
arr = [0, 1, 2, 3, 4, 5, 6]
k = 1
arr[~k] # 5; returns second element form the end because ~1 == -2- Bitwise shift left
<<:- Shifts all bits of a number to the left by a specified number of positions.
- Any bits that exceed the size of the number (e.g.,
32-bit int) are discarded.- Example:
- Example:
- Example:
- Bitwise shift right
>>- Shift all bits to right
- All bits on right which exceed number size are discarded
- - same as integer division by :
- - same as integer division by :
- Example:
Comparison of bitwise operations
1 0 1 1
┌────────────
AND │ 0 1
OR │ 1 1
XOR │ 1 0Operations precedence
~>>,<<&^|
Example
Common operations
- Make bitmask with all
1's of lengthn(forn = 4,mask = 0b1111):1 << n - 1~(~0 << n)~- 2 ** n:2 ** n- Same with1 << n-- Make negative number.Remember, negatives are stored as Two-s complementc = ~n + 1~- Since complement inverts bits, we revert them back
- Check if
nhas at least same1s ask:n & k == k
- Set
n-th bit with1:num = num & 1 << n
- Set
n-th bit with0:num = num & ~(1 << n)
DFS#
If undirected tree, visited array ont needed because we can just track previous